IO
Background
We are moving our workloads from HDFS to AWS S3. As part of this activity we wanted to understand the performance characteristics and costs of using S3.
Seek vs Read
One particular scenario that stood out in our performance testing was Seek vs Read when dealing with S3.
In this test we are trying to read through a file
- Seek to Point A in the file read X bytes
- Move to Point B in the file that is A + X + Y
- This is accomplished as another seek or as a read
- We will leave Y variable to determine when this is best
- Read X bytes
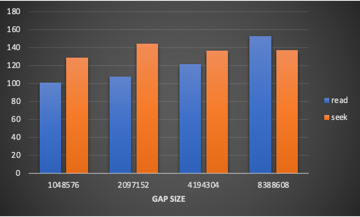
Observations:
- We could clearly see that a read is more performant than seek when dealing with steps/gaps smaller than 4 MB.
- At 4 MB read is faster by ~ 11%
- At 1 MB read is faster by ~ 20%
- Reads are also cheaper as we perform a single GET instead of multiple GETs from AWS S3 Pricing
- Cost for GET: $0.0004
- Cost for Data Retrieval to the same region AWS EKS: $0.0000
ORC Read
Based on the above performance penalty when dealing with multiple seeks over small gaps, we measured the performance of ORC read on a file.
File details:
- Size ~ 21 MB
- Column Count: ~ 400
- Row Count: ~ 65K
| Read Type | Duration | Unit |
|---|---|---|
| All Columns | 1.075 | s |
| Alternate Columns | 6.489 | s |
Observations:
- We can clearly see that we pay a significant penalty when reading alternate columns, which in the current implementation of ORC translates to multiple GET calls on AWS S3
- While the impact of penalty will be less significant in large reads, it will incur overheads both in terms of time and cost
Read Optimization
Approach
The following optimizations are planned:
- orc.min.disk.seek.size is a value in bytes: When trying to determine a single read, if the gap between two reads is smaller than this then it is combined into a single read.
- orc.min.disk.seek.size.tolerance is a fractional input: If the extra bytes read is greater than this fraction of the required bytes, then we drop the extra bytes from memory.
- We can further consider adding an optimization for the complete stripe in case the stripe size is smaller than
orc.min.disk.seek.size
Scope
Different types of IO takes place in ORC today.
- Reading of File Footer: Unchanged
- Reading of Stripe Footer: Unchanged
- Reading of Stripe Index information: Optimized
- Reading of Stripe Data: Optimized
Each of the above happens at different stages of the read. The current implementation optimizes reads that happen using the DataReader interface.
This does not:
- Optimize the read of the file/stripe footer
- Reads across multiple stripes
Benchmarks
Local FS
This benchmark is run on the local filesystem with NVMe SSD, so it has very different performance characteristics to AWS S3.
The purpose of this benchmark is to ascertain if we have added any significant penalties in the ORC code by adding
minSeekSize and extraByteTolerance.
java -jar java/bench/core/target/orc-benchmarks-core-*-uber.jar chunk_read
| (alt) | (cols) | (byteTol) | (minSeek) | Mode | Cnt | Score | Sign | Error | Units |
|---|---|---|---|---|---|---|---|---|---|
| true | 128 | 0.0 | 0 | avgt | 20 | 0.352 | ± | 0.006 | s/op |
| true | 128 | 0.0 | 4194304 | avgt | 20 | 0.357 | ± | 0.002 | s/op |
| true | 128 | 10.0 | 4194304 | avgt | 20 | 0.349 | ± | 0.002 | s/op |
| false | 128 | 0.0 | 0 | avgt | 20 | 0.667 | ± | 0.007 | s/op |
| false | 128 | 0.0 | 4194304 | avgt | 20 | 0.673 | ± | 0.004 | s/op |
| false | 128 | 10.0 | 4194304 | avgt | 20 | 0.671 | ± | 0.005 | s/op |
Observations/Details:
- Input File details:
- Rows: 65536
- Columns: 128
- FileSize: ~ 72 MB
- Full Read (alternate = false)
- No significant difference between the options as expected
- Alternate Read (alternate = true)
- No significant difference between the options given the small file size and performance of local disk
- This also calls out that the recommended minSeekSize should be determined for each platform e.g. HDFS, S3, etc
AWS S3
In this benchmark we brought up an EKS Container in the same region as the AWS S3 bucket to test the performance of the patch.
| (alternate) | (byteTol) | (minSeekSize) | Mode | Cnt | Score | Sign | Error | Units |
|---|---|---|---|---|---|---|---|---|
| FALSE | 0.0 | 0 | avgt | 5 | 1.837 | ± | 0.089 | s/op |
| FALSE | 0.0 | 4194304 | avgt | 5 | 1.919 | ± | 0.11 | s/op |
| FALSE | 10.0 | 4194304 | avgt | 5 | 1.895 | ± | 0.191 | s/op |
| TRUE | 0.0 | 0 | avgt | 5 | 5.8 | ± | 1.132 | s/op |
| TRUE | 0.0 | 4194304 | avgt | 5 | 1.479 | ± | 0.197 | s/op |
| TRUE | 10.0 | 4194304 | avgt | 5 | 1.435 | ± | 0.176 | s/op |
Observations/Details:
- Input File details:
- Rows: 65536
- Columns: 128
- FileSize: ~ 72 MB
- Full Read (alternate = false)
- No significant difference between the options as expected
- Alternate Read (alternate = true)
- We get a significant boost in performance 5.8s without optimization to 1.5s with optimization giving us a time reduction of ~ 75 %
- This also gives us a cost saving as 64 GET one for each column per stripe have been replaced with a single GET
- We can see a marginal improvement ~ 3% when choosing to retain extra bytes (extraByteTolerance=10.0) as compared to (extraByteTolerance=0.0) which performs additional work of dropping the extra bytes from memory.
Summary
Based on the benchmarks the following is recommended for ORC in AWS S3:
orc.min.disk.seek.sizeis set to4194304(4 MB)orc.min.disk.seek.size.toleranceis set to value that is acceptable based on the memory usage constraints. When set to0.0it will always do the extra work of dropping the extra bytes.